| Bevy Version: | 0.9 | (outdated!) |
|---|
This entire book is outdated and no longer maintained. I am keeping it online, in case anyone still finds any of the information in it useful. To adapt to newer versions of Bevy, please consult Bevy's migration guides.
Render Architecture Overview
NOTE: This chapter of the book is an early Work in Progress! Many links are still broken!
The current Bevy render architecture premiered in Bevy 0.6. The news blog post is another place you can learn about it. :)
It was inspired by the Destiny Render Architecture (from the Destiny game).
Pipelined Rendering
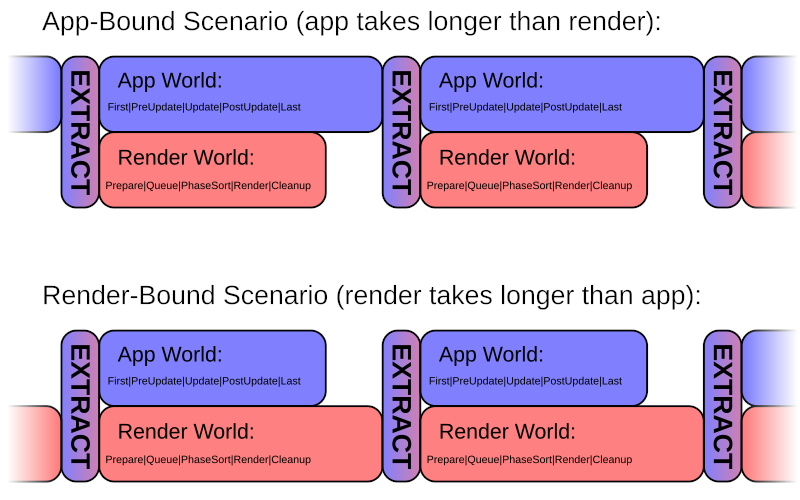
Bevy’s renderer is architected in a way that operates independently from all the normal app logic. It operates in its own separate ECS World and has its own schedule, with stages and systems.
The plan is that, in a future Bevy version, the renderer will run in parallel with all the normal app logic, allowing for greater performance. This is called “pipelined rendering”: rendering the previous frame at the same time as the app is processing the next frame update.
Every frame, the two parts are synchronized in a special stage called “Extract”. The Extract stage has access to both ECS Worlds, allowing it to copy data from the main World into the render World.
From then on, the renderer only has access to the render World, and can only use data that is stored there.
Every frame, all entities in the render World are erased, but resources are kept. If you need to persist data from frame to frame, store it in resources. Dynamic data that could change every frame should be copied into the render world in the Extract stage, and typically stored using entities and components.
Core Architecture
The renderer operates in multiple render stages. This is how the work that needs to be performed on the CPU is managed.
The ordering of the workloads to be performed on the GPU is controlled using the render graph. The graph consists of nodes, each representing a workload for the GPU, typically a render pass. The nodes are connected using edges, representing their ordering/dependencies with regard to one another.
Layers of Abstraction
The Bevy rendering framework can accomodate you working at various different levels of abstraction, depending on how much you want to integrate with the Bevy ecosystem and built-in features, vs. have more direct control over the GPU.
For most things, you would be best served by the “high-level” or “mid-level” APIs.
Low-Level
Bevy works directly with wgpu, a Rust-based cross-platform
graphics API. It is the abstraction layer over the GPU APIs of the underlying
platform. This way, the same GPU code can work on all
supported platforms. The API design of wgpu is based on
the WebGPU standard, but with extensions to support native platform features,
going beyond the limitations of the web platform.
wgpu (and hence Bevy) supports the following backends:
| Platform | Backends (in order of priority) |
|---|---|
| Linux | Vulkan, GLES3 |
| Windows | DirectX 12, Vulkan, GLES3 |
| macOS | Metal |
| iOS | Metal |
| Android | Vulkan, GLES3 |
| Web | WebGPU, WebGL2 |
On GLES3 and WebGL2, some renderer features are unsupported and performance is worse.
WebGPU is experimental and few browsers support it.
wgpu forms the “lowest level” of Bevy rendering. If you really need the
most direct control over the GPU, you can pretty much use wgpu directly,
from within the Bevy render framework.
Mid-Level
On top of wgpu, Bevy provides some abstractions that can help you, and
integrate better with the rest of Bevy.
The first is pipeline caching and specialization. If you create your render pipelines via this interface, Bevy can manage them efficiently for you, creating them when they are first used, and then caching and reusing them, for optimal performance.
Caching and specialization are, analogously, also available for GPU Compute pipelines.
Similar to the pipeline cache, there is a texture cache. This is what you use for rendering-internal textures (for example: shadow maps, reflection maps, …), that do not originate from assets. It will manage and reuse the GPU memory allocation, and free it when it becomes unused.
For using data from assets, Bevy provides the Render Asset abstraction to help with extracting the data from different asset types.
Bevy can manage all the “objects to draw” using phases, which sort and draw phase items. This way, Bevy can sort each object to render, relative to everything else in the scene, for optimal performance and correct transparency (if any).
Phase Items are defined using render commands and/or draw functions. These are, conceputally, the rendering equivalents of ECS systems and exclusive systems, fetching data from the ECS World and generating draw calls for the GPU.
All of these things fit into the core architecture of the Bevy render graph and render stages. During the Render stage, graph nodes will execute render passes with the render phases, to draw everything as it was set up in the Prepare/Queue/PhaseSort stages.
The bevy_core_pipeline crate defines a set of standard
phase/item and main pass types. If you can, you
should work with them, for best compatibility with the Bevy ecosystem.
High-Level
On top of all the mid-level APIs, Bevy provides abstractions to make many common kinds of workloads easier.
The most notable higher-level features are meshes and materials.
Meshes are the source of per-vertex data (vertex attributes) to be fed into your shaders. The material specifies what shaders to use and any other data that needs to be fed into it, like textures.